
핸즈온 머신러닝 2nd Edition
Part 1 머신러닝
Chapter 2 머신러닝 처음부터 끝까지
부동산 회사에 막 고용된 데이터 과학자라고 가정한다.
진행할 주요 단계는 다음과 같다.
- 이 글은 시리즈 글입니다. 다음 목차를 참고해주십시오. 클릭시 해당 페이지로 연결됩니다.
- 큰 그림을 본다.
- 데이터를 수집한다.
- 데이터를 탐색하고 시각화한다.
- 데이터를 머신러닝 알고리즘을 위해 수정한다.
- 모델을 선택하고 train한다.
- 모델을 Fine Tuning한다.
- 솔루션을 제시한다.
- 시스템을 Launching, Monitoring, Maintenance 한다.
데이터 가져오기
1 큰 그림 보기?
- 데이터는 캘리포니아 블록 그룹block group(미국 인구조사국에서 발표하는 데 사용하는 최소한의 지리적 단위)별 인구(population), 중간소득(median income), 중간주택가격(median housing price) 등을 담고 있다.
- 이 데이터를 이용해 특정 데이터가 주어졌을 때, 구역의 중간 주택 가격을 예측하는 것이 목표이다.
1_1 문제 정의
- 모델을 구축하는 목적은 최종적으로 부동산 투자 결정을 내리기 위해서일 것이다.
- 지금 구축하는 모델은 아래 그림에서처럼 여러가지 다른 신호와 함께 최종 투자 결정 모델의 하나의 입력으로 사용된다고 가정한다.
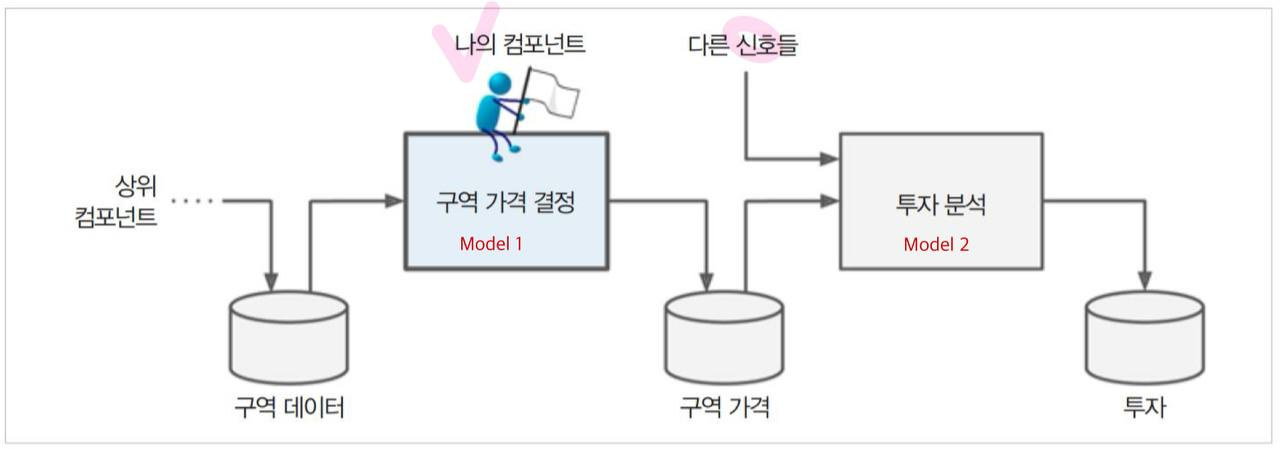
파이프라인이란?
1. 데이터 처리 컴포넌트Component들이 연속되어 있는 것이 파이프라인이라고 한다.
위 그림의 상위 컴포넌트, Model1, Model2, 다른 신호들이 모두 파이프라인의 구성요소이며 컴포넌트이다.
2. 각 컴포넌트들은 비동기적으로 동작하며 독립적이다.
- 문제 정의는 이 모델이 지도학습, 비지도학습, 강화학습 중 무엇인지, 배치학습, 온라인학습 중 무엇인지를 결정하는 문제를 포함한다.
- 레이블된 훈련 샘플이 있으니 지도학습이다. 사용할 특성이 여러개 있으니 다중회귀이다.
- 데이터가 매우 크면 맵리듀스Map Reduce를 통해 배치 학습을 여러 서버로 분할하거나, 온라인 학습 기법을 선택할 수 있다.
1_2 성능 지표 선택
- 회귀 문제의 전형적인 성능 지표는 평균제곱근오차Root Mean Square Error를 사용할 수 있다.
$$\text{RMSE} = \sqrt{\frac{1}{n}\sum_{i=1}^{n}(y_i - \hat{y}_i)^2}$$
- 이상치가 많을 경우, 평균 절대 오차mean absolute error를 사용하기도 한다.
$$\text{MAE} = \frac{1}{n}\sum_{i=1}^{n}|y_i - \hat{y}_i|$$
- 거리 측정에는 여러가지 Norm(수학적으로 벡터의 크기나 길이를 측정)이 사용될 수 있다. Norm의 개념은 다음 페이지를 참고한다.
1_3 가정 검사
- 마지막으로, 지금까지 만든 가정을 나열하고 검토해야 한다.
- 만약 이 모델에서 나온 결과값(100, 200, ....)이 숫자 그대로 사용되는 것이 아니라 ('저가', '중가', '고가') 등의 범주형 값으로 사용된다면, 정확한 가격을 구하는 것이 전혀 중요하지 않게 될 뿐만 아니라, 위 알고리즘은 회귀 문제가 아닌 분류 문제가 된다.
다음 포스트에 계속...
'Study > Hands On Machine Learning' 카테고리의 다른 글
| 핸즈온머신러닝-머신러닝이란 무엇인가 (1) | 2024.01.11 |
|---|