
본 포스팅은 다음 포스팅으로부터 이어집니다 : keras를 이용한 mnist 데이터 분류(1)
- 모델 평가하기
evaluate = model.evaluate(x_test, y_test)
print(evaluate) # [0.1212036104369623, 0.9739] [손실값, 정확도]- 학습된 모델을 통해 값 예측하기
results = model.predict(x_test)
print(results.shape)
np.set_printoptions(precision=7) # numpy 소수점 제한(7자리)
print(f'test[0]이 각 클래스에 속할 확률 : \n{results[0]}')
arg_results = np.argmax(results, axis=-1) # 가장 큰 값의 인덱스를 가져온다.
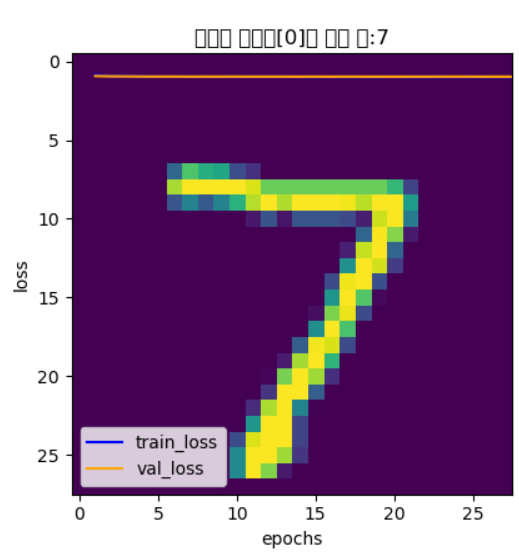
plt.imshow(x_test[0].reshape(28, 28))
plt.title('모델의 테스트[0]의 예측 값:' + str(arg_results[0]))
plt.show()test[0]을 7로 예측한 모습
혼동행렬을 이용한 모델 평가
from sklearn.metrics import classification_report, confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
# 혼동 행렬을 만듭니다.
plt.figure(figsize = (7, 7)) #
cm = confusion_matrix(np.argmax(y_test, axis = -1), np.argmax(results, axis = -1))
# y_test와 results의 numpy 행렬에서 최고 차수(-1)를 기준으로 비교하여 최고값을 선정.
sns.heatmap(cm, annot = True, fmt = 'd',cmap = 'Blues')
# sklearn의 데이터를 이용하여 heatmap을 시각화해주는 seaborn의 패키지
#
plt.xlabel('predicted label')
plt.ylabel('true label')
plt.show()-
figure(figsize = (weight, height)) : Figure dimension (width, height) in inches.
-
seaborn.heatmap(data, vmin=None, vmax=None, cmap=None, center=None, robust=False, annot=None, fmt='.2g', annot_kws=None, linewidths=0, linecolor='white', cbar=True, cbar_kws=None, cbar_ax=None, square=False, xticklabels='auto', yticklabels='auto', mask=None, ax=None, **kwargs)
-
annot : bool or rectangular dataset, optional
If True, write the data value in each cell. If an array-like with the same shape as
data, then use this to annotate the heatmap instead of the data. Note that DataFrames will match on position, not index.
→ 각 셀에 숫자를 입력 -
fmt : string, optional
String formatting code to use when adding annotations.
→d는 정수 형태의 출력을 지시 -
cmap : matplotlib colormap name or object, or list of colors, optional
The mapping from data values to color space. If not provided, the default will depend on whether
centeris set.
→ 색깔을 설정

분류보고서
from sklearn.metrics import classification_report
print('\n', classification_report(np.argmax(y_test, axis=-1), np.argmax(results, axis=-1)))결과
precision recall f1-score support
0 0.97 0.99 0.98 980
1 0.99 0.98 0.99 1135
2 0.97 0.97 0.97 1032
3 0.98 0.95 0.97 1010
4 0.97 0.97 0.97 982
5 0.96 0.96 0.96 892
6 0.98 0.97 0.98 958
7 0.97 0.98 0.97 1028
8 0.95 0.97 0.96 974
9 0.96 0.97 0.96 1009
accuracy 0.97 10000
macro avg 0.97 0.97 0.97 10000
weighted avg 0.97 0.97 0.97 10000'Python > Python 딥러닝' 카테고리의 다른 글
| [Keras]무슨옷-무슨색? ImageGenerator를 이용한 Multi-label Class Classification (0) | 2020.07.15 |
|---|---|
| Keras를 이용한 보스턴 주택가격 예측 + K-Fold (0) | 2020.07.15 |
| Keras를 이용한 mnist 숫자 데이터 분류(1) (0) | 2020.07.13 |
| Keras에서 개발 과정, 활성화함수, 옵티마이저, 손실함수, 평가지표란? (0) | 2020.07.13 |
| 파이썬_확률적 경사 하강법-SGD(Stochastic Gradient Descent) (1) | 2020.07.13 |